Kävipä tässä niin, että sain tehtäväkseni toimeksiannon, jonka päämääränä oli selvittää asiakas- ja myyntirekisterin pohjalta tietoja esimerkiksi parhaista asiakassegmenteistä ja toimialoista. Näin mielenkiintoista projektia ei ollutkaan ennen tullut vastaan, joten päätinkin tarttua heti toimeen ja otin Excel esiin!
Tiedot rakentuivat samaan tyyliin kuin varmasti lukuisissa suomalaisissa yrityksissä, eli yhdessä taulukossa oli tiedot myynneistä, toisessa tiedot asiakkaista ja kolmannessa vielä vähän lisätietoa asiakkaista.Näiden pohjalta oli tarkoitus luoda muutamia tyypillisiä raportteja, eli jakaa myynnit esimerkiksi ikäryhmittäin, sukupuolittain ja toimialoittain. Taulukkojen ainoa linkki toisiinsa oli asiakasnumero, eli ID, joten ratkaisu oli selvä: haetaan tarvittavat tiedot asiakkaista myyntirekisteriin käyttämällä VLOOKUP-kaavaa, ja luodaan sen jälkeen Pivot-taulukko, jonka avulla myyntirekisteriä voidaan pyöritellä tarpeen mukaan.
Olen käyttänyt tätä lähestymistapaa lukemattomia kertoja aiemmin, mutta en kuitenkaan koskaan näin suuressa mittakaavassa. Korostettakoon siksi näin aluksi, että tämä lähestymistapa ei ole missään nimessä väärä, vaan monessa tapauksessa itseasiassa paras vaihtoehto. Tätä lähestymistapaa käyttämällä kohtasin kuitenkin muutamia ongelmia, joita aion esitellä ratkaisuineen tässä kirjoituksessa.
1. Laskentateho
Suuria tietokantoja käsitellessä vastaan tulee auttamatta puutteet laskentatehossa. Omassa pari vuotta vanhassa läppärissäni on 2,30GHz tuplaydinprosessori ja 4,00 Gt RAM:ia, ja vaikka se ei mikään tehomylly olekaan, en ole koskaan aiemmin huomannut että Exceliä käyttäessä loppuisi tehot kesken. Tarve suurelle laskentateholle tulee siitä, kun solujen arvot haetaan toisesta taulukosta. Esimerkiksi asiakkaan nimen, iän ja paikkakunnan etsiminen VLOOKUPilla 10 000 nimen listasta 20 000 myynnille vaatii prosessorilta paljon.
Ongelmia laskentatehon loppumiseen voi ratkaista esimerkiksi asettamalla Excelistä automaattinen laskeminen pois. Tämä löytyy valikosta Formulas -> Calculation. Kun laskeminen on asetettu manuaaliseksi, voit laskea solut koko työkirjasta F9- näppäimellä tai sheetistä painamalla shift + F9.

Toinen tapa keventää taulukkoa on poistaa soluista kaavat ja jättää taulukkoon pelkät arvot. Tähän ei tietääkseni ole mitään poppaskonstia olemassa, joten helpoin tapa on (1) kopioida koko sarakkeen arvot ensin tyhjään sarakkeeseen, jonka jälkeen (2) leikkaat nämä arvot alkuperäisen päälle. Tämä konsti on sinänsä tehokas, mutta kääntöpuolena on etteivät muutokset alkuperäisessa taulukossa enää päivity.
Ai niin, tähän väliin voisi muuten mainita että ennen kuin teet mitään, kannattaa ensimmäisenä tarkistaa lähtödata, ettei kaikkea tarvitse tehdä kahteen kertaan. (Terveisiä vuoden asiakas ”asfafsafs”:lle, joka ostit tuotteita miljoonalla!)
2. Kertaluonteisuus
Äskeiseen esimerkkiin liittyen, pelkkä VLOOKUP-ja Pivot-taulukko – kombinaatio toimii huonosti pitkäkestoisessa projektissa. Koska uusien arvojen laskeminen tai hakeminen vaatii paljon laskentatehoa, käytännössä soluissa saattaa olla vain pelkät arvot. Uusien arvojen lisääminen on silloin kyllä teoriassa mahdollista, mutta vaatii melko paljon aikaa ja vaivaa – päivitys, kaavat uudestaan, kaavat pelkiksi arvoksi.
Ideaalitilanteessa taulukkoon päivittyisi tiedot uusista myynneistä ja ajankohtaiset tiedot asiakkaista helposti. Järkevin tapa onkin pitää tiedot taulukkomudossa (luodaan painamalla Ctrl + T), jolloin uudet rivit lisääntyvät dataan automaattisesti. Voit myös laskea taulukkoon uusia arvoja samaan tyyliin kuin tavalliseenkin taulukkoon. Taulukon käyttöönottoa puoltaakin erityisesti kätevämpi tapa viitata alueisiin – kun normaalit Excel-kaavat viittaavat soluun tai alueeseen, DAX-kaavat viittaavat sarakkeeseen,
Vrt:
=Count(A:A)
Laskee arvojen lukumäärän sarakkeessa A.
=Count(laskut[id])
Laskee arvojen lukumäärän taulukon ”laskut” sarakkessa ”id”.
Tavallista suuremman aloituskynnyksen vuoksi peruskäyttäjälle jää siten ainoaksi vaihtoehdoksi tietojen lisääminen kopioimalla, jonka vuoksi lopputulos on aika staattinen – käytännössä pelkkä katsaus yhteen hetkeen. Seuraavaa raporttia varten solut täytyisi laskea aina uudestaan ja uudestaan. Tämän vuoksi suosittelen lämpimästi tutustumaan Microsoft Office Excel-taulukoihin.
3. Pivot-taulukoinnin rajat
Enpä olisi etukäteen uskonut, mutta projektia toteuttaessani Pivot-taulukoinnin rajat tulivat vastaan. Ongelma ilmeni, kun oli aika selvittää toimialojen sukupuolijakaumat. Lähdin toteuttamaan tätä käyttämällä binäärinä sukupuolta (0/1) ja laskemalla tämän jälkeen toimialakohtaisesti käyttäjien sukupuolen keskiarvon. Lopputuloksena olisi silloin prosenttiluku, esim. 17%, jota tulkittaisiin siten että 17% on sukupuolta 1.
Koska moni asiakas toimi useammalla kuin yhdellä toimialalla, luvut täytyi laskea myyntikohtaisesti, eli hakea VLOOKUP:lla tieto asiakkaan sukupuolesta asiakas ID:n perusteella. Tämän jälkeen loin Pivot-taulukon, johon tuli pystyyn toimialan koodit ja niiden viereen keskiarvot sukupuolista. Eli tyyliin:
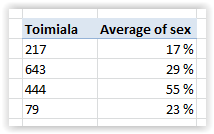
Tässä vaiheessa hälytyskellot alkoivat soimaan, sillä luvut eivät näyttäneet lainkaan oikeilta. Pienen tarkistelun jälkeen huomasinkin missä meni vikaan: koska tiedot olivat myyntirekisteristä, jokainen myynti tulkittiin taulukossa omaksi havainnoksi sukupuolesta. Eli käytännössä esimerkiksi yksi erittäin aktiivinen miesasiakas pystyisi muuttamaan toimialan sukupuolijakauman virheelliseksi.
Googlen perusteella vastassa oli yleinen ongelma, joka on korjattu Excel 2013:ssa uudella Distinct Count- mahdollisuudella. Vaihtoehdot jäävät kuitenkin vähiin vanhempia versioita käytettäessä. Koska luvut olivat raportoinnin kannalta todella oleellisia, oli aika improvisoida. Ratkaisin tämän laatimalla ensin Pivot-taulukon kaikista käyttäjistä toimialalla, kopioimalla sen uuteen taulukkoon ja laatimalla näistä arvoista jälleen uuden Pivot-taulukon. Ratkaisu oli hieman kiven alla, mutta pääasia on, että luvut pitivät paikkaansa.
Lopputulos:
Ottaen huomioon kohdat 1, 2 ja 3, Excel peruskäytössään on hieman rajoittunut raportointityökalu. Onneksi raportointimahdollisuuksia on kuitenkin mahdollista laajentaa Business Intelligenseä tai muuta useamman taulukon analyysiä ajatellen hyödyntämällä Excelin DAX-kaavoja. Koska nämä ovat kuitenkin aivan oma juttunsa, niiden käyttäminen vaatii perehtymistä.
Toinenkin mielenkiintoinen asia tuli esille. Usein siitä kuulee puhuttavan, mutta vasta tätä projektia toteuttaessa todella ymmärsin miksi Power Pivot-lisäosa on niin suosittu. Esimerkiksi kohdassa 3 esitelty Distinct Count on tällä hetkellä mahdollista laskea Power Pivotilla yhtä helposti kuin tavalliset Count ja Sum – arvot. Myös arvojen hakeminen eri taulukoista on huomattavasti helpompaa Power Pivotilla. Siksi suosittelen kokeilemaan ilmaista Power Pivot-lisäosaa, jonka saat ladattua Microsoftin sivuilta.
Excel 2010:lle täältä.
Mitä ajatuksia tämä kirjoitus herätti? Minkälaisia ongelmia sinä olet kohdannut Pivot-taulukoissa?